第三篇说成员变化,有了对选举和日志复制的认识,这个模块就很轻松简单了。
成员变化就两种情况,增加删除更换节点,和转移领导人。
1、更改一般节点
第三篇说成员变化,有了对选举和日志复制的认识,这个模块就很轻松简单了。
成员变化就两种情况,增加删除更换节点,和转移领导人。
日志复制是所有分布式共识算法最重要也是最复杂的部分,需要考虑各种各样安全性,比如机器挂了持久化没做、网络分区导致term&logindex不一致、成员变化带来两个任期相同的leader、异步网络出现日志乱序等等。
很多个细节,我边看源码边照着论文理解,一个异常判断反复推敲它的作用,想象发生的场景。这是源码级熟悉raft的好处,多多少少能身临其境,获取更多的实战校验。
后面至少还有两篇,成员变化和日志压缩。
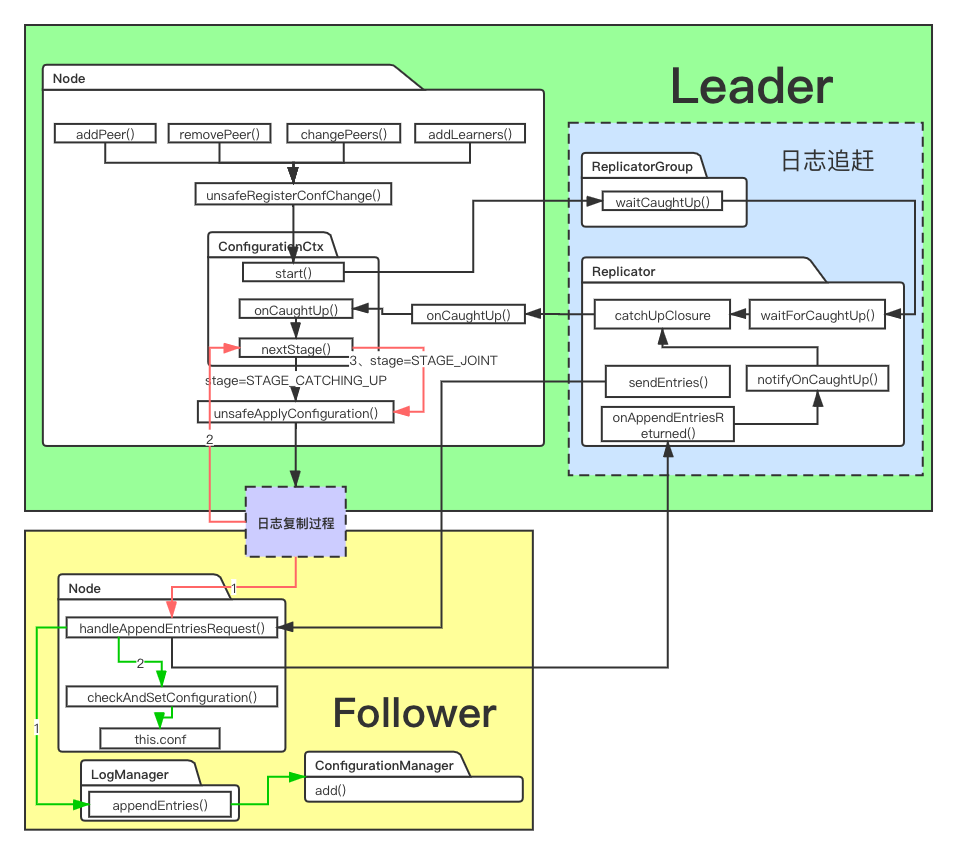
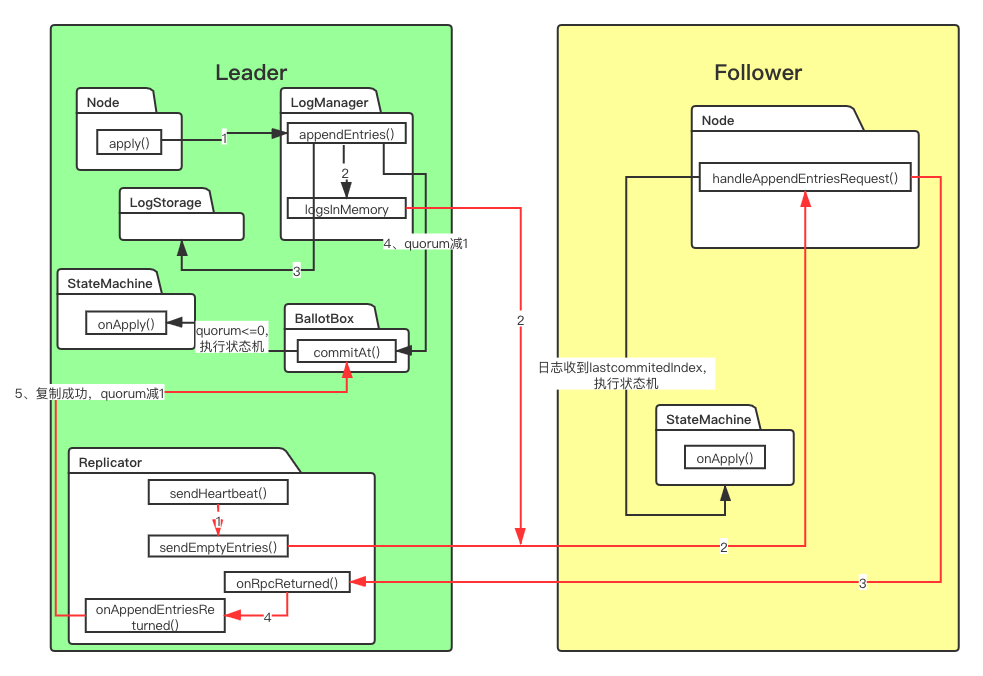
花了点时间做张较为直观的简化流程图,红色箭头是日志复制的过程。还是挺复杂的,包括不限于Node、LogManager、Replicator、BallotBox、StateMachine之间的调用,其实还有快照,以后再讲。
本文会分为三部分讲,写请求日志落盘、日志复制、commit执行StateMachine。
最近潜心cap理论和raft算法,选用了蚂蚁金服的sofa-jraft,深入研究具体的实现。该框架参考自百度的BRAFT,可以说是非常优秀的分布式通用框架,很值得学习。
Raft算法的理论就不再多说了,感性认识的话可以看这个动画,非常好懂。
示例在github的jraft-example
| |
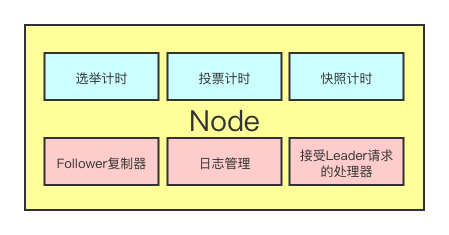
分布式系统关键单体就是节点Node,它包括raft分布式算法中需要的所有行为,不限于选举、投票、日志、复制、接收rpc请求等,梦开始的地方。
$ kubectl describe pod/apigateway-6dc48bf8b6-clcwk -n cn-staging
Normal Killing 39s (x735 over 15h) kubelet, 10.179.80.31 Killing container with id docker://apigateway:Need to kill Pod
可能是磁盘满了,无法创建和删除 pod
处理建议是参考Kubernetes 最佳实践:处理容器数据磁盘被写满
博客前面分享了一篇《分享一个 Nginx 正向代理的另类应用案例》,时隔不久,身为救火队员、万金油的博主又再一次接到了一个奇葩需求:
场景和上次有些类似,也是部门引进的第三方应用,部署在各个网络区域,从 OA 办公区域无法直接访问。目前,运营人员都需要登陆 Windows 跳板机,才能打开这些应用的 WEB 控制台。既不方便,而且还有一定 Windows 服务器的维护工作量,于是找到我们团队,希望通过运维手段来解决。
拿到这个需求后,我先问了下各个应用的基本情况,得知每个应用的框架基本是一样的,都是通过 IP+端口直接访问,页面 path 也基本一样,没有唯一性。然后拿到了一个应用 WEB 控制台地址看了下,发现 html 引用的地址都是相对路径。
乍一想,这用 Nginx 代理不好弄吧?页面 path 一样,没法根据 location 来反代到不同的后端,只能通过不同 Nginx 端口来区分,那就太麻烦了!每次他们新上一个应用,我们就得多加一个新端口来映射,这种的尾大不掉、绵绵不绝事情坚决不干,Say pass。
再一想,我就想到了上次那个正向代理另类应用方案,感觉可以拿过来改改做动态代理。原理也简单:先和用户约定一个访问形式,比如:
Nginx 代理地址为 myproxy.oa.com,需要代理到 IP 为 192.168.2.100:8080 的控制器,用户需要访问 http://myproxy.oa.com/192.168.2.100:8080/path。
TCP 连接的 CLOSE_WAIT 状态,正常情况下是短暂的,如果出现堆积,一般说明应用有问题。
每个CLOSE_WAIT连接会占据一个文件描述,堆积大量的CLOSE_WAIT可能造成文件描述符不够用,导致建连或打开文件失败,报错too many open files:
| |
检查系统CLOSE_WAIT连接数:
| |
检查指定进程CLOSE_WAIT连接数:
| |
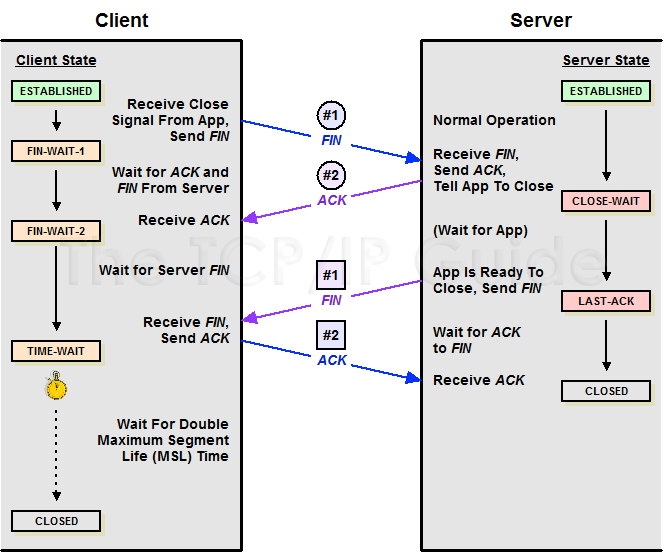
我们看下 TCP 四次挥手过程:
| |
| |
| |
| |
系统如果出现 IO WAIT 高,说明 IO 设备的速度跟不上 CPU 的处理速度,CPU 需要在那里干等, 这里的等待实际也占用了 CPU 时间,导致系统负载升高,可能就会影响业务进程的处理速度,导致业务超时。
使用top命令看下当前负载:
| |
%wa(wait) 表示 IO WAIT 的 cpu 占用,默认看到的是所有核的平均值,要看每个核的%wa值需要按下 “1”:
朋友弄了一个小项目,要我帮忙做下 Linux 系统运维,上线一段时间后,发现项目偶尔会挂掉导致服务不可用。 开发朋友一时之间也没空去研究项目奔溃的根因,只好由我这个运维先写一个项目进程自拉起脚本, 通过 Linux 任务计划每分钟检查一下进程是否存在来避免项目挂了没人管的情况。
自拉起脚本很简单,随便写几行就搞定了:
| |
然后丢到 crontab,1 分钟执行一次:
| |
-_-不过进程还是挂了